Seamless Data Sharing Using Amazon Redshift
Introduction
What is Amazon Redshift?
- Amazon Redshift is a fast, fully managed, petabyte-scale cloud-based data warehouse service. It makes it simple and cost-effective to efficiently run your analytics workloads at scale.
- Amazon Redshift uses columnar storage (also known as columnstore) to store your data in columns instead of rows, which allows it to make more efficient use of storage space and compute resources than traditional row-oriented databases like MySQL or PostgreSQL.
- In addition to its performance benefits, columnar storage also enables fast queries based on specific values within each column–for example: “find all customers who ordered product X between dates Y1 and Y2.”
What is Amazon Redshift Data Sharing?
- Amazon Redshift Data Sharing is a feature that enables Redshift cluster owners to share live data across different Amazon Redshift clusters, accounts, and regions.
- With data sharing, users can easily and securely share data with other Redshift users, without having to copy or move the data.
What are Amazon Redshift Data Sharing Benefits?
- Data sharing is a great way to improve your security and performance, as well as save money.
- Enhanced Security - By using Amazon Redshift data sharing, you can ensure that only authorized users have access to sensitive data by limiting the number of tables they can access. This helps prevent accidental or malicious disclosure of confidential information during queries and analysis.
- Improved Performance - Data sharing improves query performance by allowing multiple users with different privileges to access the same table simultaneously without affecting one another’s results or causing errors in the query plan generated by SQL queries run against it (for example, if two people were trying to run a join on two distinct tables).
- Cost savings - Sharing data across accounts and regions can help to reduce data storage costs and eliminate the need to move data.
- Data sharing is a great way to improve your security and performance, as well as save money.
Amazon Redshift Data Sharing Architecture
The architecture for data sharing is built on RA3 nodes with Redshift managed storage.
Data can be shared at many levels including databases, schemas, tables, views, columns and user-defined functions to provide fine-grained access controls that can be tailored for different users and businesses that all need access to Amazon Redshift data.
Please find below the architecture diagram for Amazon Redshift Data Sharing:
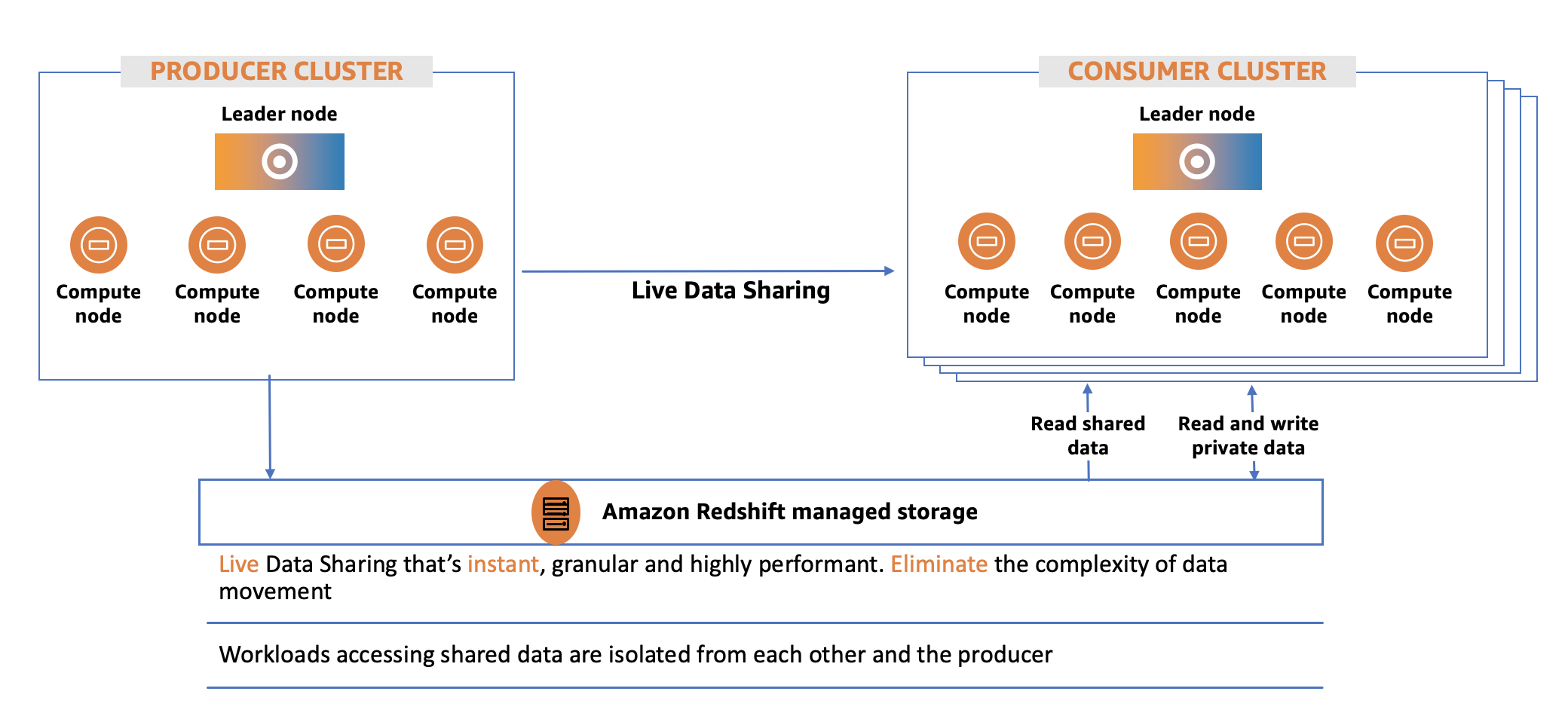
Data sharing between Amazon Redshift clusters is a two-step process.
First, the producer cluster administrator that wants to share data creates an Amazon Redshift datashare. The producer cluster adds the needed database objects such as schemas, tables, and views to the datashare and specifies a list of consumer clusters to share the datashares.
Following that, privileged users on consumer clusters create an Amazon Redshift local database reference from the datashare made available to them and grant permissions on the database objects to appropriate users and groups. Users and groups can then list the shared objects as part of the standard metadata queries and start querying immediately.
How to use AWS Redshift Data Sharing?
AWS Redshift Data Sharing enables the sharing of live data across Redshift clusters, accounts, and regions in a secure and controlled manner.
To use AWS Redshift Data Sharing, you can follow these steps:
- Create a Redshift cluster: - you can create a Redshift cluster either in your own AWS account or in a different AWS account.
- Set up data sharing: - In the Redshift console, enable data sharing for the cluster by creating a data share. You can select the data to share and specify the accounts and regions with which you want to share the data.
- Invite accounts: - Once you have set up a data share, you can invite AWS accounts to access the data. You can choose to grant read-only access or read-write access to the data.
- Access shared data: - Once the accounts have accepted the invitation, they can access the shared data using their own Redshift clusters. They can run queries on the shared data and create views and materialized views.
- Manage data sharing: - You can manage data sharing by modifying the share settings, revoking access to a share, and monitoring share usage.
Amazon Redshift Data Sharing Use Cases
Amazon Redshift data sharing is especially useful for below use cases:
Workload Isolation:
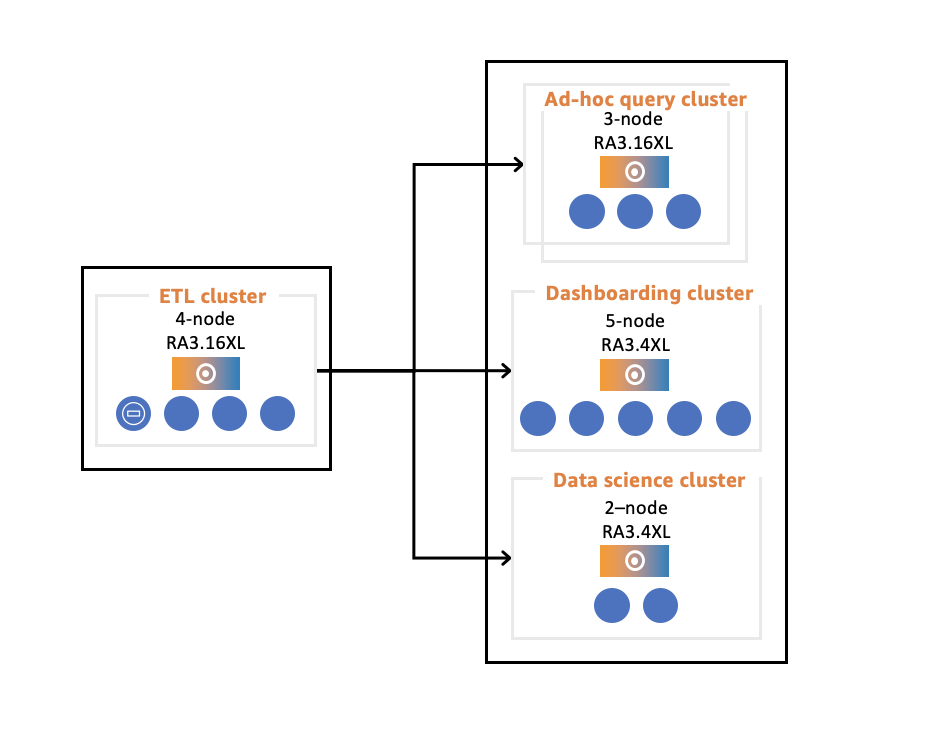
- Customers can use Amazon Redshift Data Sharing feature to isolate their workloads. Customer can get following benefits with workload isolation:
- Rapidly onboard new analytics workloads
- Size and scale individual workloads according to their performance requirements
- Provide workload isolation while sharing common datasets
- Offer chargeback for individual workloads
- Pause / resume producer and consumer clusters as necessary
- Customers can use Amazon Redshift Data Sharing feature to isolate their workloads. Customer can get following benefits with workload isolation:
Enable Cross-Group Collaboration:
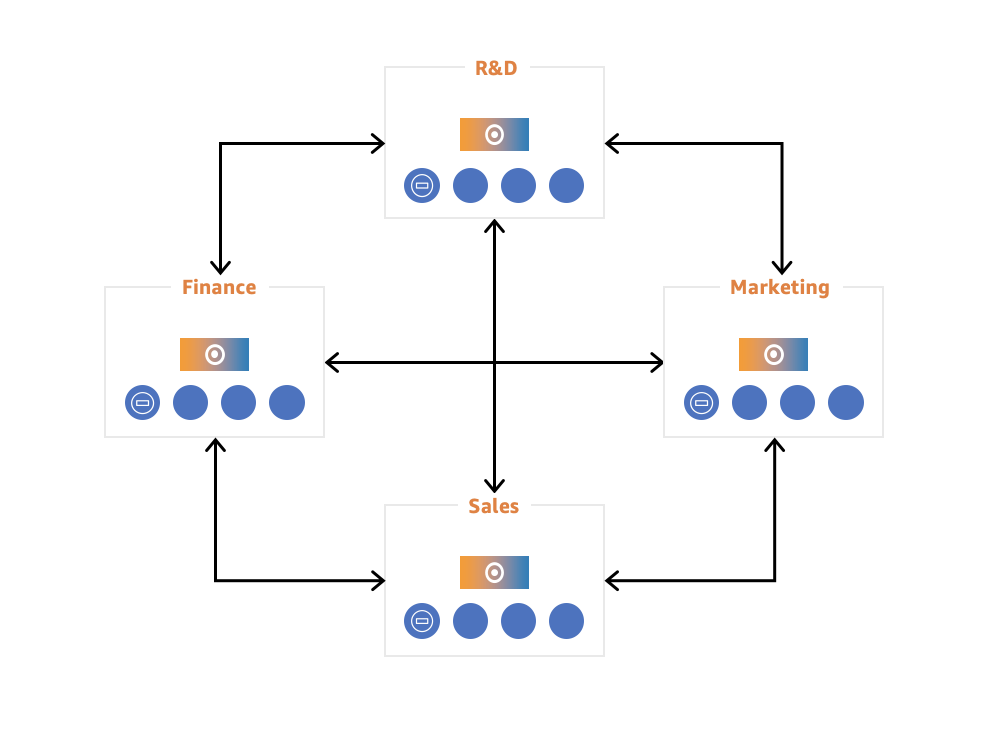
- Customers can use Amazon Redshift Data Sharing feature to enable seamless collaboration across teams and business groups for broader analytics, data science, and cross-product impact analysis.
- It also eliminates the compliance concerns of moving data between different Amazon Redshift clusters.
Deliver Data as a Service:
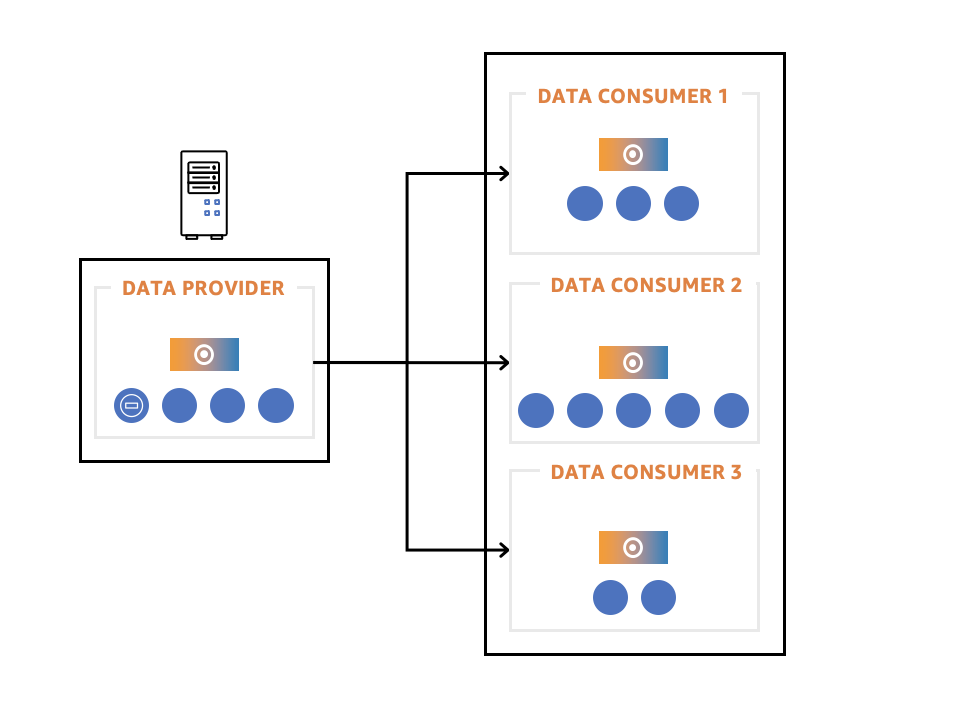
- Customers can use Amazon Redshift Data Sharing feature to offer data and analytics as a service within and across organizations and also with external parties. Customers can get following benefits with data sharing while delivering Data as a Service
- Securely share live data with Amazon Redshift clusters in same or different AWS accounts
- Monitor / track usage of the data and retain control of the data sets
- Customers can use Amazon Redshift Data Sharing feature to offer data and analytics as a service within and across organizations and also with external parties. Customers can get following benefits with data sharing while delivering Data as a Service
Share Data between Environments:
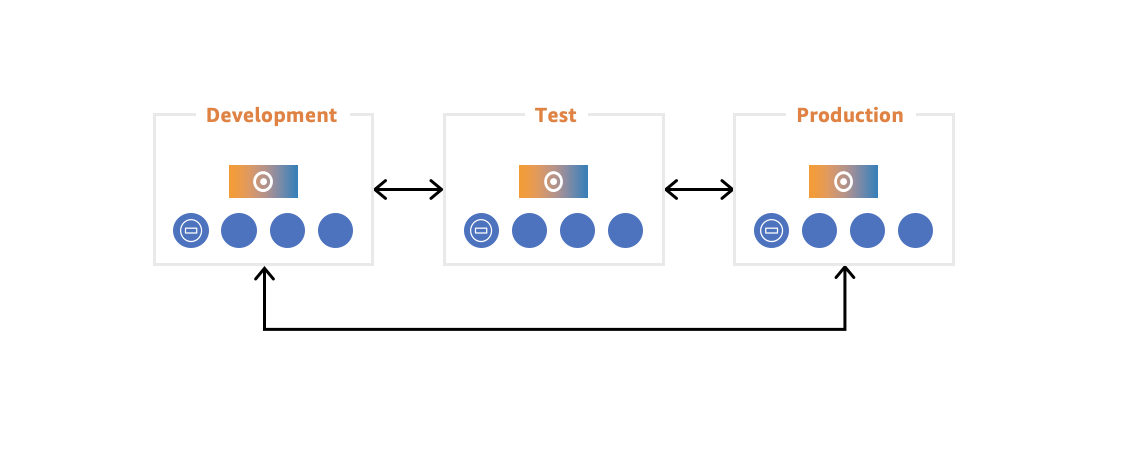
- Customers can improve agility of teams by sharing data between development, test, and production environments at any granularity.
Resources
- Visit this page to find the latest documentation.
Conclusion
- In this article, we’ve covered the benefits of using Amazon Redshift to share data with your team. We’ve also covered how to set up your environment and get started with a demo database.
- As you can see, sharing data between different users or teams is easy with Redshift. You can use it to share information across departments within your organization or collaborate with external partners by making their data available in a secure way that meets their needs.
- The next time you need to access or share large amounts of information, consider using Amazon Redshift!